
Thank you to Mike Frischmann (our Director of Evaluation Engineering) for contributing to this week’s Rant.
Eight hundred pound gorilla alert! Energy efficiency program evaluation “best practices” need a big overhaul. I am not talking about best practices for doing impact evaluation like the Uniform Methods Project. It’s disgusting that so much money is spent on standards like that and others, while ulterior motives drive program evaluation in entirely different directions.
Purpose of Program Evaluation
The State and Local Energy Efficiency Action Network, aka SEE Action’s Energy Efficiency Program Impact Evaluation Guide, states the following are objectives of program evaluation.
- Document the benefits (i.e., impacts) of a program and determine whether the subject program (or portfolio of programs) met its goals.
- Identify ways to improve current and future programs through determining why program-induced impacts occurred.
- Support energy demand forecasting and resource planning by understanding the historical and future resource contributions of energy efficiency as compared to other energy resources.
Oh, really?
They forgot this one;
- Don’t look for fear of what might be behind the door and white wash the results to make the program administrator look good.
Crotchety old man with a shameless self-promotion alert: there is nothing we like to do more than fulfill, to the best of our ability, the objectives noted in SEE Action’s impact evaluation guide as noted above. Unfortunately, more often than not (that’s right, I said it), useful findings that would otherwise, uh, report accurate net impacts of the program, improve the program and accurately support load forecasting, are kicked to the curb.

Silence of the Lambs
If you missed this movie, too bad. Get it. Jodie Foster’s character, Clarice Starling, is no ordinary FBI rookie. She means business, and she’s going to get the killer. If she were a program evaluator in many jurisdictions, she would have simply pulled up to the curb next to Buffalo Bill’s house to take a gander. Nope. Nothing here. Let’s head on down, retire early to the hotel, and check in with headquarters. No. You have to open some doors, face the music, and chase the lead until you get to the bottom of it. Many times when we open the doors, we find, “oooh, this doesn’t look so good, does it?”.
However, as described a few weeks ago in Evaluating Custom Efficiency, Clarice is not allowed to get out of the car, let alone open the door to see the rat.
If site visits aren’t completed, that’s exactly what you have – a drive-by, Potemkin Village impact evaluation.
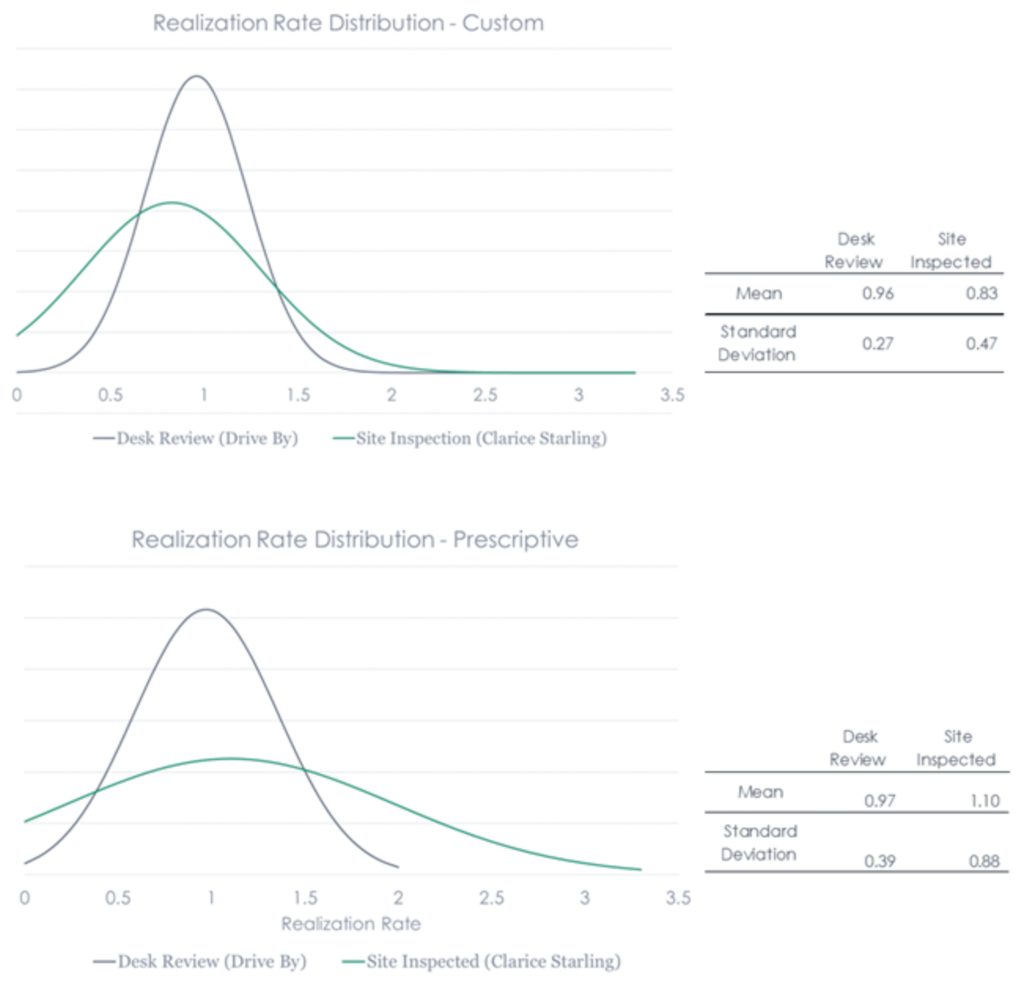
Let’s look at some data from an IEPEC paper we produced several years ago. Data shown in the chart clearly indicates Clarice finds a lot more behind closed doors than a drive-by evaluation does.
Let’s start with sample size. As I have pointed out in previous posts, drive-by evaluations require smaller sample sizes because there is much more certainty in the results. If we don’t look at anything, guess what, we find no errors – certainty! Just look at the normal distributions bell curves on the charts. The drive-by results show nice tight bell curves.
Wannabe Sampling Experts – Listen Up!
One thing buyers of evaluation often pick at and get hung up on is sampling. A ratio called the coefficient of variation – the ratio of standard deviation to the mean – is guessed ahead of time to determine sample size. Well, look at the difference in drive-by results versus site-inspected. Nobody considers THAT! Ninety-ten ruse alert!
Calling All Statisticians
Clarice costs more than the drive-by impact evaluation – maybe twice as much, but do we want the truth or a false sense of bell curve bliss?
As I noted in Real Time Evaluation for Real, 90/10 sampling[1] requires about 80 projects for evaluation. To minimize cost, there may be 40 projects that get drive-by reviews only while 40 get the Clarice treatment. How, statistician, do you mix results of the green curves above with results from the black curves above and get anything meaningful?
How?
I get it. It’s messy, but why paper over reality and pretend it’s all wonderful? What good does that do anyone?
The Future is Next Week
The variance of regulatory oversite and monitoring by regulatory agencies is not unlike the politics from state to state across the fruited plain. They include:
- Requirements to do evaluation only. Regulators have no seat at the table nor do they even get to see the report.
- Evaluations on behalf of the regulators who are actively involved, pushing back on evaluation results.
- Third party, independent evaluators where evaluators evaluate evaluators doing the evaluations. (I got that right)
- Evaluations for portfolios administered by third parties at the behest of regulators.
- Evaluations for non-profit state administrators.
- Evaluations for utility administrators doing their own implementation or hiring contractors to do
Next week, we will get into some differences in evaluation philosophy under these models. We will also discuss how results matter much more when efficiency is used as a resource and for load forecasting. It’s amazing how suddenly accuracy (not to be confused with precision) becomes important when efficiency is actually used in planning!
[1] Ninety percent confident that the true answer for the entire population lies within plus or minus 10% of the sample results.
